
Michael Buckbee
23 Sep 2024
Pssst - want to skip right to the chart? click here
We're Wafris, an open-source web application firewall company that, among other frameworks, ships a Rails middleware client.
At launch, the v1 client required a local Redis datastore to be deployed with your app. We're now releasing v2 of our Rails client which uses SQLite as the backing datastore.
This article covers the decision-making that went into our migration from Redis to SQLite, performance considerations, and architectural changes. Continue reading this if you're interested in the decision-making that went into our migration to SQLite from Redis for our clients (the deployed middleware)
These data stores are not drop-in replacements, and if you try to do that, you'll have a bad time. This article walks through the testing and decision-making that went into rearchitecting our v1 Redis-based client to our v2 SQLite-based client.
Since day one of Wafris, our goal has been to make it as easy as possible for developers to protect their sites.
But our v1 has had mixed results in delivering on that promise. We made what we thought at the time was a solid choice to back the Wafris client with a user-owned (bring your own) Redis datastore.
Partially, this was due to our having come up in the Heroku ecosystem, where Redis is an easy click away to get going and deployed in such a way that it's easy to access remotely. We also looked at successful projects like Sidekiq, which had a similar model.
If we're trying to make things easy on you, we shouldn't casually make you a Redis database admin in the process.
But the ecosystem is much larger than that, and many of our users encountered Redis deployment issues that were difficult to debug and fix.
In other words, if we're trying to make things easy on you, we shouldn't casually make you a Redis database admin in the process.
Further, when we exhibited at RailsWorld 2023, there was a definite "blood in the water" vibe regarding Redis and the assumption that you'd automatically need a Redis server running alongside your Rails application.
While Redis is "fast" in comparison to traditional RDBMS, it's still a database that you have to manage connections, memory, processes, etc., which introduces more brittleness into the stack (the opposite of what we're trying to achieve).
And more than any of those, if you're in a cloud environment, you're looking at network latency. Network delays are a big deal for us as every inbound HTTP request to your app must be evaluated against the rules stored in Wafris. So while we sweated blood and code to get our v1 client as fast as possible, we'd often wind up in situations where, despite our best efforts, we'd still slow down an application as the network the app was provisioned into was slow.

While there certainly exist wholly distributed applications out there, and while most Rails apps are "majestic monoliths" (tm? idk, don't sue me), we've found a lot of distributed apps that messed up our assumptions.
Apps that deploy to multiple zones, split functionality into servers with overlapping responsibilities, or are only partially Rails and deployed alongside other languages or frameworks.
Mostly, things aren't that clean in production, introducing even more friction with using Redis.
Wafris is a web application firewall. In Rails, it's installed as a middleware. It lets you set rules like "block the IP 1.2.3.4," and then when someone requests your site, you evaluate that request against those rules.
Imagine it's this simplified two-step process:
Abstractly, this is a paired "read" of the rules in the database (step 2) and then a "write" of the report detailing what was done with that request along with its data.
From a logical standpoint, the first "read" half of this process is vastly more important than the latter "write" half:
Others have written far more eloquently about what SQLite is suitable for in general than I could ever hope to do so myself, so on that topic, I'll point you to the following resources:
As noted above, our major bottleneck is network IO, and Stephen mentioned this line from the SQLite documentation: "SQLite does not compete with client/server databases. SQLite competes with fopen()."
SQLite does not compete with client/server databases. SQLite competes with fopen().
In theory, this should be much faster than a Redis solution solely based on cutting out the network round trip.
So, we decided to benchmark SQLite vs Redis.
Benchmarking is a dark art of deceiving yourself with highly precise numbers.
And benchmarketing datastores is even more fraught. Every single flipping database benchmark I've ever seen has been covered in a layer of asterisks and qualifications, and the comments on HN are full of "if you'd just set this flag when compiling it, you'd get 3% more speed out of reads, and the fact that the people running this didn't do this is proof that they were paid off and that they actively sell shady NFT scams of deranged yacht rock Harambe memes.

However, we have an advantage here. We're not trying to get some absolute number of speed under pristine conditions and carefully tweaked settings. We are creating a wildly specific and biased benchmark against our own data in a use case that lends itself to some extremes that I would neither expect nor hope that anyone else would have to deal with.
We're trying to optimize for people throwing Wafris into their app and having it "Just Work™" (ok, this one might actually be trademarked).
We're also not testing against some theoretical benchmark suite (that can be gamed ala NVIDIA).
We're testing the hot path of our own application and our worst query.
Our worst query is a somewhat complicated request for a "lexical decimal" data structure that maps IP ranges (v4 and v6) against categories. The simplest to consider is IP -> Country mapping, where we return the country if an IP address is within a range of two addresses.
It's terrible because these structures are, by necessity, large (millions of rows), and in the case of IPv6, every single entry is huge.
To make this happen, we precompute the range lookups and then wrote them to:
For each inbound HTTP request, we, in the pathological case, have to check the requesting IP against:
This is what we mean by "hot path"—this singular query type is so important that we can ignore all the rest of the query types and functions.
So, for our benchmarking scripts, we tested only this one query type, saving us days of work porting more significant (but irrelevant to the hot path) portions of the app to the benchmark.
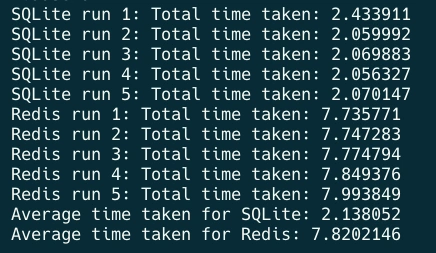
Testing was done on my local Macbook Air M2 with a homebrew installed Redis and local SQLite db.
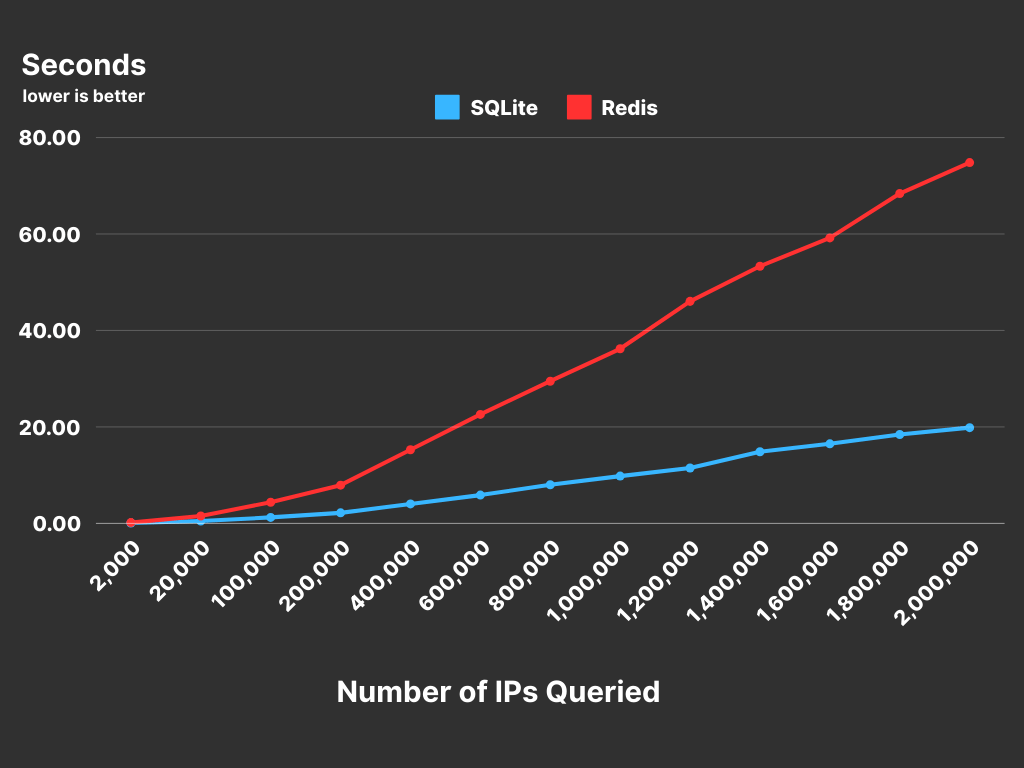
SQLite beat Redis like an overhyped UFC fighter doing a jump off the fence to land a kick punch (for our particular use case in this niche)
SQLite was roughly a 3x speed improvement over a locally deployed Redis instance. YMMV. Note again that this is before any network latency is considered.
From our perspective, this was a fantastic result as even if SQLite were only on par with Redis locally, we'd still win by being able to entirely axe network times.
I'd like to stress again that this is extremely flawed testing (by design) with really naive settings, but it is done in a way that mirrors the flaws of real-world usage we observed.
Benchmarks exist in a vacuum. What the chart fails to capture is that:
We're focused on:
Everything else flows from that, so that's what we're rearchitecting towards. NOT "the best database setup," not "the easiest infrastructure for us (Wafris) to manage," etc.
Great, so now that we've established that SQLite is faster than Redis (caveats, caveats, caveats), everything still isn't great because there are real-world tradeoffs.
One huge tradeoff in the testing above is that we didn't even consider doing any writes.
While it's never really stated, the whole reason for a "proper" database to have connections, connection pools, transactions, and whatever proprietary magic allows Oracle to charge a billion dollars for a database is to manage writes contending with reads for data in your database.
Consider an electric Chinese supercar driven by a charming British man - it's fast, it's fantastic, and it is absolute bollocks at hauling a load of concrete blocks across town.

SQLite is like that NIO EP9 supercar. We need to use it for what it's good at and not force it into a role it's not suited for.
On v1 (Redis), the update loop looked like this:
This obviously won't work with SQLite because we can't "push" a SQLite database to a web server. There are some newer SQLite as a service providers that let you do a version of this, but for a variety of cost, performance, and security considerations, it won't work for us as we'd still need individual users to deploy them, open ports, allow inbound connections, etc.
On v2 (SQLite), the update loop looks like this:
This works well as it removes much of the user's installation and configuration responsibility.
We're seeing a ~3x increase in successful installs of the v2 client.
Consider a Rails app deployed to a cloud provider (AWS, Heroku, Fly, etc). with autoscaling enabled.
Your requests go from 100 req/s to 10,000 req/s. and your compute (dynos, machines, ec2 instances) start spinning up to handle the load, but does your database?
The answer is almost certainly no because a bottleneck is a bottleneck without the database, and while you could overprovision it by 100x "just in case," realistically, nobody wants to do that.
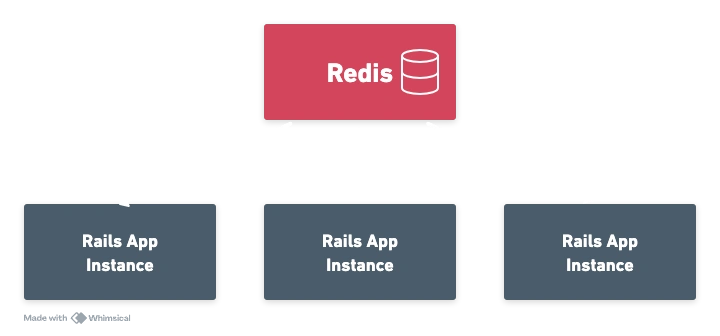
In practice, this is the number one thing that we see kill Rails apps under heavy load. Rarely is it an actual DDOS attack; more often, it's a credential stuffing attack or a bad bot that is hammering a site, pushing up autoscaling that's then exhausting database connections, which causes the app to fall over.

Flipping this to a system where an SQLite DB is synced down to each compute instance solves this problem excellently by keeping all the calls local to the new compute instance.
We started this article by discussing splitting the app into a read (rule evaluation) and write (reporting) path and then studiously ignored the write path.
We did rearchitect the write path to do the following:
Which will work for approximately 0% of everybody else, but we don't care about them.
We care about the 100% of our users who want the Wafris client to be easy to deploy and stupid fast.
It's hard to know if there's a lesson you can learn from reading all of this, but we sincerely appreciate you taking the time.
First: thanks to Aaron Francis, Travis Northcutt, Brian Hogg, Dave Ceddia, Peter Bhat Harkins and Nate Bosscher for their feedback and suggestions on this post.
Second: we're exceedingly happy with our v2 architecture, which uses SQLite. It's already helped many sites weather attacks and stay online.
It's much easier to get going, with less support work for us and less hassle for users, which we think is a win for a safer, more secure internet.
Start blocking traffic in 4 minutes or less